For those of you who like such things, this post explores the rationale and methodology for my work on London Lives Petitions: it’s a revised/extended version of my paper at the Digital Humanities Congress, September 2016, in the session on Adding Value: Challenging Practical and Philosophical Assumptions in the Digitisation of Historical Sources. You can also find the slides here (pdf).
Introduction
If there’s one assumption I’d like to challenge here, it’d be that the digitisation of historical sources is all about this sort of thing:
Working on massive online history resources (Old Bailey Online, London Lives, Connected Histories, The Digital Panopticon, et al) has been keeping me occupied for the last 10 years; I very much like that state of affairs and I believe deeply in the importance of the work my colleagues and collaborators and I do at the Humanities Research Institute. But I also believe that online resources are just one facet of the digitisation of history. Our work should be a beginning, part of ongoing dialogues, adaptations and conversions, not the final word.
The good news is that both Old Bailey Online and London Lives data have been getting remixed almost as long as they’ve existed. For example, they were included in the federated search project Connected Histories, the GIS project Locating London’s Past, and in our current, massive record linkage project Digital Panopticon. And not just by us: there is the Old Bailey Corpus, and Old Bailey Online is also in the federated search sites 18thConnect and NINES. It’s also recently started attracting the attention of mathematicians and statisticians and this year has been used as a resource in a course on Scalable Data Science.
Re-use of the London Lives data outside our own domain is much less extensive, but parts of it have been used by Adam Crymble, Tim Hitchcock and Louise Falcini for a project and dataset on 18th-century vagrant lives (which we’re including in Digital Panopticon). And in fact it was their project and approach to data sharing that really got me thinking about the possibilities of remixing London Lives data on a smaller scale than our huge collaborative (and hugely funded) projects: extracting and reshaping sub-sets of data that are more manageable but nonetheless too large (tens of thousands of records rather than hundreds or low thousands) to work with entirely by hand. The London Lives Petitions Project (hereafter LLPP) is one of the results.
London Lives
London Lives is a major digital edition of a range of primary sources about eighteenth-century London, with a particular focus on the poor and crime. The project’s approach to digitisation was designed around an explicit research agenda: to foreground the lives and experiences of non-elite people and to de-emphasise institutions. More practically, the scale of the enterprise necessitated a pretty single-minded discipline to get it done. Of course we aimed to create a resource with more general usefulness, but those were the key conceptual and material factors underpinning source selection and setting the priorities for how sources would be digitised.
That meant: full text transcription followed by marking up in XML to make specific things searchable: the names of people and places, dates and occupations or social status, to facilitate nominal record linkage. And not (for example): paying detailed attention to institutional categories or structures, or cataloguing documents as archivists might do.
The result is a website (as the name suggests) that makes it easy to look for people, link together records about an individual’s life and even group related people together. But it can be harder to use for subjects that are related by other categories or themes. The keyword search is basic; there are no features to save and link, say, documents or places rather than names.
Also, the emphasis is on human judgment to make those links, and to answer questions like: what kind of person is this; how does this tagged name relate to other potentially relevant pieces of information in its vicinity? It’s been hard work to convert London Lives data for use in Digital Panopticon, which needs heavily structured name data for record linkage. So in the last couple of years we’ve been thinking a lot about ways to restructure, enhance, and build on the work we began a decade ago.
The other thing to note about London Lives is that we had to put a range of different kinds of records into a single framework, and some fitted better than others. Many of the records were bound volumes, coherent institutional products – registers, minute books, accounts, etc. A register for example is already quite structured, even when not tabular in layout; there is little ‘narrative’ language and you know what kind of info will appear where on each page.
But then there are the Sessions Papers.
18th-century Sessions of the Peace, presided over by magistrates, oversaw a wide range of administrative work in addition to criminal justice, including poor relief, trade and work regulations. They sat several times a year and after each meeting, the clerks would file assorted stuff from that session’s business into bundles that, ultimately, add up to a massive body of very diverse records. From three London courts (Middlesex, City of London and Westminster), London Lives has around 1250 session files (950 from the Middlesex Sessions, dwarfing all the rest) amounting to 86,000 document images, which include lists and calendars, witness examinations, petitions, court orders, accounts, and all sorts of miscellanea. (The Old Bailey Sessions Papers add another 13000 or so images but only about 20 petitions.)
Finding Petitions
Petitions are among the most common documents in those files: as it turns out, around 10,000 of them. Why are petitions interesting? The humble petition was everywhere in early modern Europe. Petitions were instigated by institutions, by groups, and by individuals, by elites and by paupers, and all sorts of people in between, direct appeals to powerful institutions or individuals to resolve a grievance or crisis. So they tell stories about lives and experiences; they aim to persuade, often to play off one source of authority against another. (work in progress bibliography)
The surviving documents are in many ways a pale shadow of the original interaction; we usually don’t know who actually wrote them, or how the voices of the petitioners might be filtered and mediated. Nonetheless, they have something to tell us about the agency of the governed and their relationships with and expectations of governments.
But also petitioners’ stories, however creative, had to conform to some formal conventions, employ certain forms of language. As a result, petitions form a potentially meaningful and findable textual corpus – if I could find the right strategies.
Just one example to underline why searching the London Lives website wouldn’t be that strategy (quite apart from scale!).
A keyword search of London Lives for ‘petition’ in Middlesex Sessions in the year 1690 returns 8 results, including 2 documents that are not petitions (although they are related). But the same keyword search and constraints in the current version of the LLPP dataset finds 11 petitions. And in total there are 66 petitions from Middlesex Sessions in that year.

[Confession time: I screwed up this example in the presentation; I said the total in LLPP for MiddS+1690 was 11, rather than 66. I somehow managed to forget the 11 results were only those including ‘petition’. Which is quite some difference. I thought it seemed low at the time…]
Why does the search miss so many? Many London Lives documents contain spelling variations, abbreviations, and not a few rekeying errors (which are not quite like OCR errors, but can cause similar problems for machine-readability). In fact, about one third of the LLPP petitions overall don’t contain a text string spelled ‘petition‘ at all. Others do, but only as part of a longer word (‘petitioner’, etc), which the London Lives search would only find with a wildcard search (which is unavailable at the time of writing).
I put the texts into the neat little linguists’ concordancing tool Antconc to get a wordlist, which indicates there are, in total, several hundred possible variants of words with the stem ‘petition’. In fact it’s not really as bad as that suggests, since there are a small number of particularly common forms (and often a petition text will contain slightly varying repetitions, so at least one of the common forms is likely to occur somewhere). The two endings -tion or -con will find 90-95% of petitions. So, I could handle this particular issue without too much trouble by searching with regular expressions.
But unfortunately that doesn’t deal with the problem of false positives. Many pages in the Sessions Papers that are not petitions contain ‘petition’ in some form: in fact if I simply search the entire Sessions Papers for ‘petition’ or ‘peticon’, my search will return more than 5000 pages that are not actually petitions (or in some cases, are continuation pages of multi-page petitions).
Keyword searching, extended with regular expressions, was a useful starting point for exploration, and it also highlighted just how many related documents the SPs actually contain – more than I think I’d realised. But I would obviously need a slightly smarter approach to identifying petitions.
So here’s a pretty typical petition, highlighting the formula parts of the document around the actual complaint of this petitioner. [I’ve already discussed how they work rhetorically in this earlier blog post but here I’m thinking about how they function as markers of document structure.]

The example shows the elements or markers that are common to petitions (notwithstanding various minor spelling/word order variations) and aid both identification and location of start and end of the petition itself when there can be various annotations before and afterwards, including signatures:
- start (1): “To The Right Honourable/Worshipful/similar title…” [After “to the”, this line can be very variable; and also it’s quite often missing or damaged]
- start (2): “The humble petition of” [appears in the majority of petitions; ‘humble’ is sometimes omitted, and there can be a lot of small but annoying spelling variations]
- start of the main body of petition: “Humbly Sheweth that” (again, ‘humbly’ is optional).
- additionally, it’s worth noting that in the body of the text petitioners almost always refer to themselves in third person: “your (humble/poor) petitioner(s)”. ‘Humble’ and ‘humbly’ will appear somewhere along the line.
- the ubiquitous ending (though again it can have quite a lot of small variations): “And your petitioner(s) (as in duty bound) shall ever pray etc“
So there’s plenty there to track them down much more reliably (and, moreover, to identify their component parts), making it possible to let the computer find the bulk of easy ‘typical’ petitions and definite ‘not’ petitions, leaving a smaller set of ‘maybes’ for more manual sifting: a few hundred, rather than several thousand.
And there are plenty of petitions that depart from the “typical” model to some degree: they might omit, or truncate, some of the expected conventions, use particularly idiosyncratic or archaic spellings, or have been penned by scribes whose handwriting was less than fluent (which is in turn likely to affect accuracy of rekeying).
Loyal readers of this blog may recognise this example:

(The phonetic “sh” spelling in petitioner is really unusual: it appears in just 8 petitions in LLPP. The entire petition is full of equally unusual spellings, and I’m pretty sure Ester wrote her own petition – the signature matches the rest – which is also very rare.)
In the end, the “non-typical” only amount to around 4-5% of petitions. But they are a little different from the rest. They skew towards the first half (and possibly the first quarter) of the 18th century (as do variant spellings of ‘petition’), and towards petitioners I’m particularly interested in, lower-status individuals and women. Not perhaps by much: women make up 20% of identifiable petitioners in the ‘typical’ 95%, and 25% in the non-typical 5%; a small number overall, but for me, doing women’s history, finding those extra 100-odd women, like Ester, is quite a big deal.
Besides, at the very beginning, it wasn’t clear just how many non-typical petitions there would be – it could have been nearer 5000 than 500 (mind you, then I’d have been looking for a different method!). But it didn’t take long to establish that they would be a relatively small number, and I do think that in a different context – if this work had been part of a much larger project working to tight deadlines – it would be a valid decision not to spend substantial amounts of time sifting manually to find those hard cases – as long as you were transparent about your methods and their limitations. But for my own purposes, and my own satisfaction, I could weigh up that choice differently – as long as I remember that, however much I’m drawn to petitions like Ester’s, they are atypical. (And I do at least know in what ways they’re atypical, and can quantify that difference.)
So, having got this data…
What Now and Next
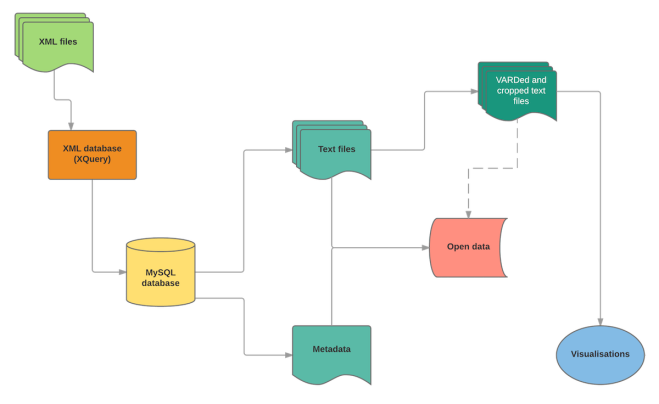
A key element of the project has been sharing and documenting the data and the research in progress:
Firstly, the open data contains some fairly basic metadata for the petitions and the corpus of plain text files. (This has been released in stages; I deliberately put some initially very rough work in progress out there for a couple of reasons. I’m as prone as any historian to getting bogged down in perfectionism; making public much less than perfect data is slightly painful, but creates incentives to improve it rather than keep hiding it away. I think it’s also a practical way of emphasising how data creation is a process rather than an event, and underlining the importance of versioning and documentation.)
There has also been further processing of the data for analysis (some of which will end up in the open data):
a) work on the petition texts, primarily “VARDing” and trimming. VARD is a great tool: like a spell checker, but for early modern English. It’s trainable, though I was impressed at its accuracy straight out of the box. It makes mistakes; I wouldn’t use it to “correct” transcriptions; but it’s ideal for making a more regular version of the data for textmining and quantitative analysis. VARDing was followed by stripping out annotations, signatures and so on at beginning and end of petitions, for example to enable analysis of petition lengths (nb: link is a dataviz that may be slow to load).
b) work on improving the metadata, especially
- separate individuals’ petitions from institutional (especially ‘parish’) ones
- using the existing London Lives name tagging to identify petitioners and start linking petitions to related records
- in particular, I want to link petitions to related documents in the SPs, especially orders, so that I can examine responses – these don’t exist for all petitions but there do seem to be a lot more than I initially was aware of; as well as to related records elsewhere in London Lives, like pauper examinations .
Finally, something I’ve not really got very far with yet: identifying what petitions are about and exploring meanings. (Some early attempts at topic modelling didn’t work very well, another reason I needed to create the VARDed and trimmed version of the data.) Other sessions on text analytics and linguistic tools at the conference gave me new ideas, although this still feels like a whole new and slightly intimidating challenge.
Concluding Thoughts
“Remixing” digitised history is something that historians do all the time, when they search online resources and copy whatever results seem relevant into their own spreadsheets and databases. But I’m not sure that they’re always doing it with the best tools for the job, or with the critical understanding they need of those resources and their limitations. Laborious “search-select-copy-paste” is fine if a resource is simply a supplement to your main sources. It becomes less appropriate if the resource is your main source, you’re using it on a large scale, or you intend to make quantitative (including implicitly quantitative) arguments based on the results. It is possible to use online search critically, but difficult without some knowledge of the underlying sources, the ability to compare different resources for the same material, and/or the time and willingness to explore different searches and methodically compare results (for a brilliant example, see Charles Upchurch, ‘Full-Text Databases and Historical Research: Cautionary Results from a Ten-Year Study’, J. Soc. Hist, 2012 [link]).
On the other hand, self-conscious digital historians (and digital humanists) are making strong critiques of online search as a methodology. “Search struggles to deal with what lies outside a set of results”, as Stephen Robertson points out. Ted Underwood argues, similarly, that “Search is a form of data mining, but a strangely focused form that only shows you what you already know to expect”.
But it seems to me that Digital Humanities-based answers to this problem often focus on the application of advanced distant reading techniques to the interpretation of Big Literary Data. I think those critiques and techniques are vitally important, but even so, the usefulness of learning how to employ them can seem rather less obvious to a social historian grappling with creating some usable research data out of digitised forms of the archival detritus of governance than to those lucky bastards screwing around with a million books (pdf). Miriam Posner has argued that what many digital humanities scholars really need, before they can get on to the fun stuff, is a lot more help with and tools for finding, cleaning and modelling data. (As she says, and Adam Crymble reminded us at the session, ‘that garbage prep work‘ is Digital Humanities too!)
The London Lives Sessions Papers can in one sense be considered big data in that there’s too much material for a person, realistically, to read all of it manually (and make sense of it). But they aren’t Big Data like a million books is Big Data. And having eventually made my dataset, I certainly want to try out that kind of analysis on the petitions texts and explore what’s possible; but I also need to do nominal record linkage and to study petitioners. My methodology for discovering petitions has been, when you get down to it, an extended kind of search. But at least for working on data creation at this sort of medium-to-biggish scale, once you’re freed from the constraints of a large database optimized for web delivery, you can get a long way screwing around with search.
