Performing and Resisting Power in Early Modern Life
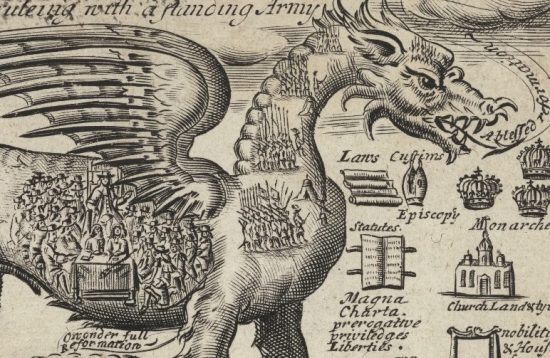
Plate 1 from Thomas May, Arbitrary government displayed to the life, 1690. Image from The Folger Shakespeare Library (www.folger.edu)
Online Symposium, 19th May 2023
Call for Papers:
Ideas, acts and practices of power were intrinsic to all levels of early modern life. This online conference will explore, question and evaluate how power was constructed, resisted, performed and undone across local, national and international spheres, through language, text, politics, technology, kinship, kingship, literature, and more. It will promote discussion that crosses disciplinary boundaries such as history, language, literary studies, material culture, art history, among others, considering the ‘known’ from new perspectives and shedding light on lesser-discussed dimensions of society and culture between 1450 and 1700.
We invite 20 minute papers from scholars that engage with the above themes from any discipline. Submissions from PhD and early career researchers are very much encouraged!…
It’s Day of Digital Humanities 2022. (I’m not sure if I’ve ever done anything to mark a #DayOfDH. I’m probably cleaning data most years. I rather enjoy cleaning data, but that doesn’t mean I want to write about it.)
This year, I’m mostly doing TEI XML markup for the Alice Thornton’s Books Project and today is the day I decided I needed to get on with some date tagging. (If I’d started it a couple of days earlier, I could have been trying out this R timelines package. Ah well.)
I’ve already done some date tagging on the smallest of Alice’s four books but it needs finishing, and I’ve got to do the biggest of the books (in terms of length), “Book One” (project working title, aka My First Book of My Life). This book comes in at somewhere near 100,000 words.
Well, I am not going to read through every word of this book looking for a few hundred taggable dates.
Instead, I’m going to use search strategies based on regular expressions (aka regex or grep), search tools provided by the OxygenXML Editor, and my knowledge of Alice’s writing patterns (and early modern dates more generally). I’m not attempting anything very sophisticated in computing terms. All I want the computer to do is narrow down how much text I have to wade through to the bits that are most likely to contain dates and present it in a nice compact form (and also, because it’ll be an iterative process, not show me stuff I’ve already tagged). I choose the search terms and I make the decisions.
Alice writes dates (or date-able pieces of text) in various ways, with some fun spelling quirks. Here are a few, fairly randomly from the resulting tagged text:
October 23 1641
Octb. 23 1641
Tuesday the 3 of Janeuary
Jan. 3 1654
About a weeke before my full time
the 14 of february
18 of May. 1655
May: 19 1655
Satterday morning
1660
June 11 1660
Shrove Sunday 61
For all the variety, this can be boiled down to some common patterns that will find nearly all the dates in the text in a few hours’ work.
year
month
week day
ordinal numbers (1st, 2nd etc, bearing in mind that, like a lot of early modern people, Alice often writes things like 2d or 3th)
feast days
for relative dating, words like “before” and “after”; “on” is really too common in the text to be very useful as a keyword, but I might try it out when I’ve done more efficient searches.
I know that virtually every date in the texts is 17th century (there’s a handful of late 16th-century dates), and I know that a lot of Alice’s dates will contain a year, so that’s the starting point. With a very simple regex, I can find every four-digit number that looks like a year between 1600 and 1699: \b16\d\d\b
This is not a regex tutorial, but by way of quick explanations: \b represents a word boundary (a space or punctuation) and \d represents any single number. So the regex will find almost every year in the list above, but it’ll ignore most other sorts of small or large numbers that might turn up in the text. It won’t be fazed by dates written in the early modern form 1665/6, because the / also counts as a word boundary. (The only one in the list that it won’t find is the final 61, a less common form, and for that I can do a second quicker scan for something like \b[2-6]\d\b.)
The year regex gave about 200 results, which are presented in Oxygen as a compact list with the search term highlighted:
(Not all of those are part of the text itself; Oxygen has extra options to limit results further to the content of tags and ignore stuff in inline comments, which I eventually remembered to turn on.)
It’s a straightforward (if fairly dull) task to work through the list and tag all the results that are really dates (most of them, hooray).
Not all dates in the list contain a year, however, and some do but the regex fails for some reason (eg, there is already some sort of tagging within the year text). But I now have a set of tagged dates, which I can inspect for the ways that Alice spells and abbreviates months, days and so on.
So the second iteration involves looking for dates that have months but not years (or the years were missed by the regex). Here’s the months regex, which handles nearly all Alice’s spelling quirks without producing a totally unmanageable number of false positives:
The results for this one are messier (I could have split it up to do terms like “may” that produce a lot of false positives separately).
But there’s one more thing I need to do now, because I want to avoid seeing all the dates I already tagged. Regex aren’t enough for this. Thankfully, Oxygen has an option to further restrict searching with an XPath expression.
This is the line of XPath code: //*[not(descendant-or-self::date)]|//text()[not(ancestor::date)]. What does it do? Um, good question. I can do basic XPath, but I’m kinda crap at this sort of slightly more advanced query and I borrowed this one off the internet (but for once, not Stack Overflow). But basically it tells the search to only look for stuff that’s not inside a <date> tag.
From here, I worked through each of the listed elements, devising a workable regex strategy each time. (Want to look for the early modern feasts that end with “mas”? mas\b does a decent job, though it also returns people called Thomas. There are quite a lot of Thomases in Alice’s world.) By the time I get to “before”/”after”, or trying out “month” “day” “year”, I’m getting steeply diminishing returns (hundreds of results, hardly any taggable dates) and it’s time to call it a day. This job is not finished yet, but I’ve done the bulk of it, and there are four of us on the team who will be working on these texts over the next several months, with plenty of opportunities for catching the harder cases. For now, there are 285 tagged dates in the big text and 250 in the small one. All I have to do now is add the TEI attributes like @when for standard date formatting. (I was going to do that this afternoon but I wrote this blog post.) And then, finally, I’ll be able to play with that timelines package.
So, there you have my Day of DH 2022: doing the stuff that makes the fun stuff possible.
Some readers may have noticed that my Early Modern Resources website has been down for a couple of months now. I’m rebuilding it, but it’s going to be a little while. In the meantime, here is a google spreadsheet of about 150 online primary source collections from the EMR database.
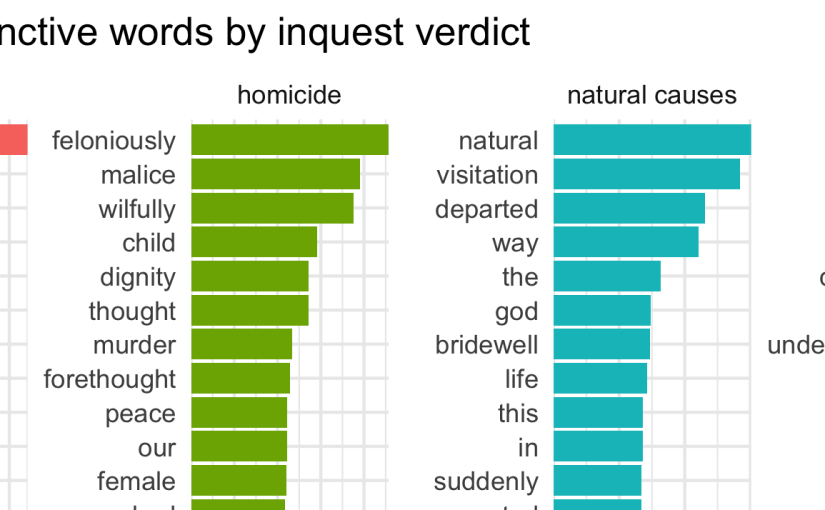
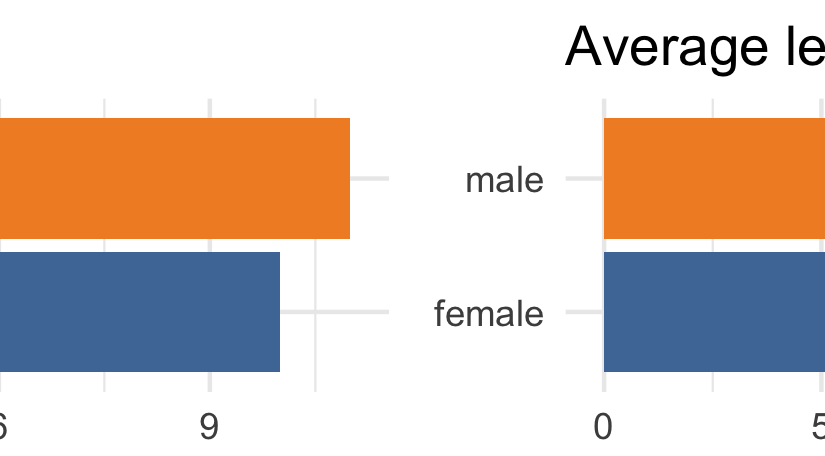
This is the second of a two-part series about the Westminster Coroners’ Inquests data. See part 1 for more detail about the source of the data, and my initial explorations of the summary data.
This post focuses more on the text of inquisitions (the formal legal record of the inquest’s findings and verdict). …
My first efforts at interactive data visualisations go back several years to some incredibly frustrating attempts to get the hang of D3.js. These were, with hindsight, doomed because (a) I didn’t really know any javascript, and D3 isn’t easy javascript; (b) I was really only just getting the hang of manipulating data… D3 was just overwhelming in terms of both code and data.. …
Cleaned-up and slightly extended version of a paper presented at the conference Gender and Violence in the Early Modern World (University of Cambridge, 23 November 2019).
She had had unjust warrants against them, claiming to be afraid of “bodily harm”. This was “greatly astonishing” to the petitioners, who were “well known never to have disturbed her majesties peace” or threatened Anne herself.
Anne had come to Allys’s house early one morning and sneakily “convaye[d] her selffe into the house to doe some outrage upon” Allys, and finding her alone,
did assault and treade her the sayd Allys (beinge an aged woman) under feete and would her have murdred or otherwayes fouly intreated yf she hadd not bine prevented by [Margery] whoe hearinge the crye came imediatly…
This was “a matter soe shamfull and unnaturall, as the lyke by anie woman hath seeldome bine offred in anie [christian?] cuntrey or towne”. Further, Anne was a frequent disturber of the peace, causing many “unseemly” brawls and affrays, and upsetting the “best sort” of the town’s inhabitants.
As a result, Allys could “not be at peace within her owne house” and was “much affrayd” of further attacks; and so they prayed both to be released from Anne’s warrants against them and for the authorities to take action against Anne.
Some elements of the case are really unusual: the language – “shamfull and unnaturall… the lyke by anie woman hath seeldome bine offred” – as well as their demand for the magistrates to “brydle the outragousnesse of the sayd Anne Lingard”. There’s nothing quite like this in any of the other petitions.
Nonetheless it reflects a number of common themes in petition narratives by victims of violence:
a background context which includes malice and vexatious litigation, disordered behaviour (versus the quiet law-abiding victim);
at least one central, murderous, assault on weak, defenceless victims;
fear of further attacks and therefore the urgent importance of bringing the offender under control.
This post for Women’s History Month 2020 explores the Bluestocking Corpus of Elizabeth Montagu’s letters, created by Anni Sairio.
This first version of the Bluestocking Corpus consists of 243 manuscript letters, written by the ‘Queen of the Blues’ Elizabeth Montagu between the 1730s and the 1780s. Elizabeth Montagu (née Robinson, 1718-1800) was one of the key figures of the learning-oriented Bluestocking Circle in eighteenth-century England. …
Among its many other wonders, you can find a marvellous run of 16th- and 17th-century CSPD on the Internet Archive. But they’re not consistently titled, and there are duplicates of many volumes, so it’s not easy to piece them together. I made a chronological list while I was preparing a sample of State Papers petitions for the Power of Petitioning project, so it may be helpful to share it. (For R users, I found the Internet Archive package and this rOpenSci tutorial very helpful.)
TNA guides, including how to convert reference in the calendars to modern references:
I think there’s a complete run of CSPD from 1547 to 1660, after which I’ve found only a handful of volumes. (There are three volumes of calendars for the interregnum Committee for the Advance of Money, but I don’t know whether any other Committees were calendared separately from the main run of commonwealth CSPD; if so, they’re not included.) There may be more volumes I didn’t find, and if I learn of any more I’ll update the spreadsheet.
The url is for the volume’s main page on the Internet Archive, from where you can access a PDF, OCR’ed text version and other formats.
Several calendars have multiple copies with separate pages; where this is the case they’re listed in the additional_ids column. If you want to try one of these instead of the main listing (the choice was arbitrary; some copies might be better quality than others), just copy and paste the id of your choice into the search box.