The London Lives Petitions project is exploring approximately 10,000 petitions (and petitioning letters) addressed to magistrates which survive in the voluminous records of eighteenth-century London and Middlesex Sessions of the Peace which were digitised around 2008 by the London Lives project (of which I was the project manager). These documents have been difficult to access within the existing London Lives online resource because of the sheer size and variety of the Sessions Papers documents. So, the first few months of the project focused on the challenge of discovering and identifying petitions in the Sessions Papers; the resulting data, consisting of structured metadata and plain text files, has been released as open data under a Creative Commons licence. (The bulk of this effort is complete, but work is ongoing to improve the data where possible.) The data and documentation of the process can be found here.
Moving on to analysis of this new data, I’m starting from the question: What can you do with 10,000 petitions? Can large-scale ‘distant reading’ techniques tell us things that we didn’t already know from close reading of smaller, personally-crafted collections of petitions? I’m experimenting with various methods and data visualisations. But I also need to consider: what can you not do with them? Understanding what doesn’t work for data like this will be important. For one thing, the quality of the transcriptions does not match up to traditional scholarly standards: is it good enough for data mining? (This and other limitations of the original data are documented on London Lives.) With this in mind, I’ve so far done a number of mostly boring but useful things:
- Processing with VARD2, a tool “designed to assist users of historical corpora in dealing with spelling variation”. This has not been intended to produce ‘better’ transcriptions (and it has probably introduced some errors along the way), but it has been very useful for dealing with common variants (eg “peticon”) and creating cleaner texts for analysis.
- Identifying and removing marginal annotations and other additions that were not part of the main body of the petition texts, and some purely formula elements (like “Middx SS” at the beginning of many documents).
- Breaking petitions up into their structural elements (which was important for my last post).
Additionally, as I’ve discussed in an earlier blog post, the survival of petitions (like other documents in the Sessions Papers) “could be haphazard and dependent on the preferences of individual clerks”. What is actually being counted? So, it’s necessary to put the petitions in their archival context. The Sessions Papers were loose papers relating to the work of the Sessions of the Peace (and Old Bailey from 1755), which could include petitions, examinations (from criminal, settlement or bastardy cases), calendars of prisoners and recognizances, copies of orders, lists of vagrants, coroners’ records (before they were split off into separate archives) and much besides.
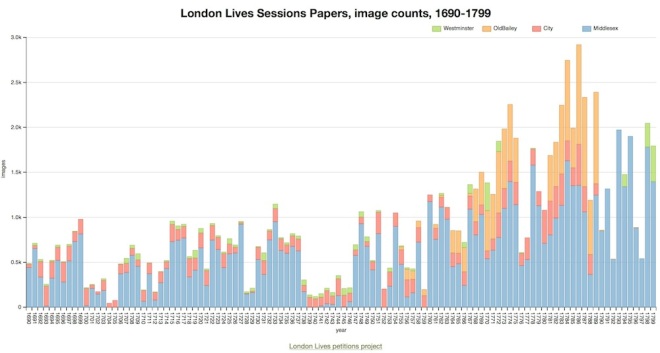
The first chart above simply shows counts of the page images in the London Lives Sessions Papers, highlighting the very uneven survival of the records, especially the nine years from 1738 when very few files have survived, and many of those which did make it contain relatively few documents (or were not fit for filming). In spite of the fluctuations, however, it also indicates quite clearly the expansion of the courts’ business, especially the Middlesex Sessions (in blue), in the second half of the 18th century. (The Old Bailey series will be excluded from further analysis because it contains so few petitions.)
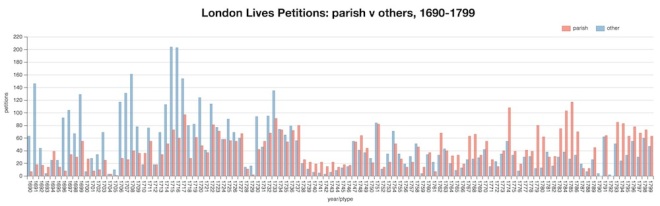
But while the Sessions Papers indicate ever growing business, petitions are on the decline (see also). This doesn’t necessarily mean there were fewer petitioners; it’s also possible that their petitions were less likely to be retained for long when there was so much more paper to deal with.

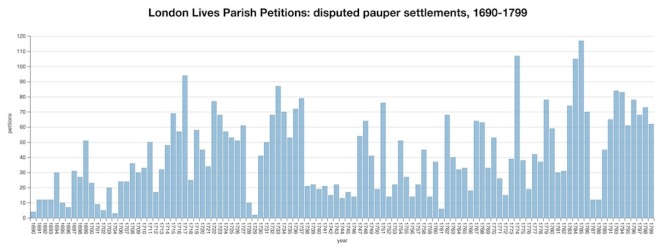
There is also a discernible shift in certain characteristics of the petitions themselves. A large group of petitions came from parish officials concerned primarily with the administration of the poor laws – churchwardens and overseers of the poor – and I’ve been working to identify and separate these ‘parish’ petitions from petitions by individuals (and a few other institutions). Most of them relate to disputed pauper removals; smaller numbers are about poor rates assessments, negligent officials, or highway repairs. Before c.1720 these constitute no more than one-third of all petitions (in most years), but from c.1760 the figure is around two-thirds, and it’s clear that ‘other’ petitions account for most of the decline in numbers. In total, the parish petitions account for about 4600 petitions (c.46% of the total), of which about 4400 are concerned specifically with removed paupers.
Here’s a typical example of one of these petitions (1760), carefully legalistic (usually drawn up by a solicitor, with careful reference to the procedures of the laws of settlement):
The Humble petition and Appeal of the Churchwardens and Overseers of the poor of the parish of Bushton in the County of Northampton Sheweth That by Virtue of an Order under the Hands and Seals of… two of his Majestys Justices of the peace for the County of Middx… Alice Wilkinson (in the sd Order) called wife of Matthew Wilkinson (if Living) was removed and conveyed from the parish of St. Clement Danes in the said County of Middx to the said parish of Rushton as the place of the last Legal Settlement of the said Alice Wilkinson Your Petitioners Conceiving themselves aggrieved by the said Order of the said two Justices of the Peace humbly Appeal to this Court against the same…
This was the petition as the voice of early modern bureaucracy rather than ‘the people’. Comparison of average word counts for parish (pink bubbles) vs other petitions (blue) also points to the former’s highly standardised character. Overall, parish petitions are only slightly shorter than the rest, but they contain far fewer unique words.

Total and unique word counts (using Antconc):
| parish | other | |
|---|---|---|
| petitions | 4618 | 5406 |
| unique words | 12385 | 30923 |
| total words | 1025567 | 1233165 |
| average per petition | 222 | 228 |
Does a comparison of the most common words in the parish and other petitions offer any insights?


Word clouds may be considered harmful by some, but I think that the contrasting appearance of the two word clouds visually enhances the more prosaic table rather well: the parish petitions use a smaller range of unique words, so the top 100 are relatively evenly sized and spaced compared to the ‘other’ petitions which are dominated by a tiny number of formula words after which frequency tails off much more quickly. [*note: a small number of very common words – eg ‘a’, ‘the’, ‘for’ – have been removed from the wordle data.]
Where next? I want to start exploring that diversity more closely. I’ll be experimenting further with corpus linguistics tools and with topic modelling. And you might have noticed the bubble chart comparing parish and other petitions suggests that non-parish petitions were not simply becoming fewer in number but also substantially longer as the 18th century went on. Might this suggest that it’s primarily petitioners of lower social status who are gradually disappearing over the course of the century, leaving primarily institutions (which generated relatively short, standard petitions) and higher status individuals (creating longer, more elaborate ones)? Whatever the answer, it’s clear that tracing changes in the petitions’ language and subjects is something that I need to be investigating further.

I’m curious, what are you hoping to find, from a historiographical perspective. Are you hoping to challenge our understanding of something in particular? Or is this exploratory?
It’s just exploration really. I want to learn to use a number of DH/distant reading tools/methods I haven’t got to grips with yet and for me this is good stuff to learn with – the texts form a nice fat coherent corpus of a very different type from the books and print material people tend to use those techniques on. Plus it’s a source I know something about but haven’t previously studied in depth. I’m not going to sit and read 10,000 petitions, so I want to explore which quantitative/distant reading/DH-y methods are most useful for getting to understand them better as a whole, to look at change over time, and identify particular kinds of petitions and petitioners for closer reading.