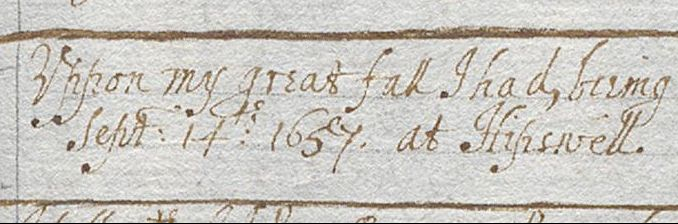
It’s Day of Digital Humanities 2022. (I’m not sure if I’ve ever done anything to mark a #DayOfDH. I’m probably cleaning data most years. I rather enjoy cleaning data, but that doesn’t mean I want to write about it.)
This year, I’m mostly doing TEI XML markup for the Alice Thornton’s Books Project and today is the day I decided I needed to get on with some date tagging. (If I’d started it a couple of days earlier, I could have been trying out this R timelines package. Ah well.)
I’ve already done some date tagging on the smallest of Alice’s four books but it needs finishing, and I’ve got to do the biggest of the books (in terms of length), “Book One” (project working title, aka My First Book of My Life). This book comes in at somewhere near 100,000 words.
Well, I am not going to read through every word of this book looking for a few hundred taggable dates.
Instead, I’m going to use search strategies based on regular expressions (aka regex or grep), search tools provided by the OxygenXML Editor, and my knowledge of Alice’s writing patterns (and early modern dates more generally). I’m not attempting anything very sophisticated in computing terms. All I want the computer to do is narrow down how much text I have to wade through to the bits that are most likely to contain dates and present it in a nice compact form (and also, because it’ll be an iterative process, not show me stuff I’ve already tagged). I choose the search terms and I make the decisions.
Alice writes dates (or date-able pieces of text) in various ways, with some fun spelling quirks. Here are a few, fairly randomly from the resulting tagged text:
- October 23 1641
- Octb. 23 1641
- Tuesday the 3 of Janeuary
- Jan. 3 1654
- About a weeke before my full time
- the 14 of february
- 18 of May. 1655
- May: 19 1655
- Satterday morning
- 1660
- June 11 1660
- Shrove Sunday 61
For all the variety, this can be boiled down to some common patterns that will find nearly all the dates in the text in a few hours’ work.
- year
- month
- week day
- ordinal numbers (1st, 2nd etc, bearing in mind that, like a lot of early modern people, Alice often writes things like 2d or 3th)
- feast days
- for relative dating, words like “before” and “after”; “on” is really too common in the text to be very useful as a keyword, but I might try it out when I’ve done more efficient searches.
I know that virtually every date in the texts is 17th century (there’s a handful of late 16th-century dates), and I know that a lot of Alice’s dates will contain a year, so that’s the starting point. With a very simple regex, I can find every four-digit number that looks like a year between 1600 and 1699: \b16\d\d\b
This is not a regex tutorial, but by way of quick explanations: \b represents a word boundary (a space or punctuation) and \d represents any single number. So the regex will find almost every year in the list above, but it’ll ignore most other sorts of small or large numbers that might turn up in the text. It won’t be fazed by dates written in the early modern form 1665/6, because the / also counts as a word boundary. (The only one in the list that it won’t find is the final 61, a less common form, and for that I can do a second quicker scan for something like \b[2-6]\d\b.)
The year regex gave about 200 results, which are presented in Oxygen as a compact list with the search term highlighted:

(Not all of those are part of the text itself; Oxygen has extra options to limit results further to the content of tags and ignore stuff in inline comments, which I eventually remembered to turn on.)
It’s a straightforward (if fairly dull) task to work through the list and tag all the results that are really dates (most of them, hooray).
Not all dates in the list contain a year, however, and some do but the regex fails for some reason (eg, there is already some sort of tagging within the year text). But I now have a set of tagged dates, which I can inspect for the ways that Alice spells and abbreviates months, days and so on.
So the second iteration involves looking for dates that have months but not years (or the years were missed by the regex). Here’s the months regex, which handles nearly all Alice’s spelling quirks without producing a totally unmanageable number of false positives:
\b(jan|feb|mar|apr|may|jun|jul|ju\.|aug|sep|oct|nov|no\.|dec)The results for this one are messier (I could have split it up to do terms like “may” that produce a lot of false positives separately).

But there’s one more thing I need to do now, because I want to avoid seeing all the dates I already tagged. Regex aren’t enough for this. Thankfully, Oxygen has an option to further restrict searching with an XPath expression.

This is the line of XPath code: //*[not(descendant-or-self::date)]|//text()[not(ancestor::date)]. What does it do? Um, good question. I can do basic XPath, but I’m kinda crap at this sort of slightly more advanced query and I borrowed this one off the internet (but for once, not Stack Overflow). But basically it tells the search to only look for stuff that’s not inside a <date> tag.
From here, I worked through each of the listed elements, devising a workable regex strategy each time. (Want to look for the early modern feasts that end with “mas”? mas\b does a decent job, though it also returns people called Thomas. There are quite a lot of Thomases in Alice’s world.) By the time I get to “before”/”after”, or trying out “month” “day” “year”, I’m getting steeply diminishing returns (hundreds of results, hardly any taggable dates) and it’s time to call it a day. This job is not finished yet, but I’ve done the bulk of it, and there are four of us on the team who will be working on these texts over the next several months, with plenty of opportunities for catching the harder cases. For now, there are 285 tagged dates in the big text and 250 in the small one. All I have to do now is add the TEI attributes like @when for standard date formatting. (I was going to do that this afternoon but I wrote this blog post.) And then, finally, I’ll be able to play with that timelines package.
So, there you have my Day of DH 2022: doing the stuff that makes the fun stuff possible.
